快速了解 Kafka 基础架构
今天来聊下大数据场景下比较流行的消息队列组件 kafka。本篇文章将主要从理论角度来介绍。
kafka 是一款开源、追求高吞吐、实时性,可持久化的流式消息队列,可同时处理在线(消息)与离线应用(业务数据和日志)。在如今火热的大数据时代,得到了广泛的应用。
整体架构
kafka 的消息以 Topic 进行归类,支持分布式 distribution、可分区partition 和可复制 replicated 的特性。下面为本人梳理的一张 Kafka 系统架构图。
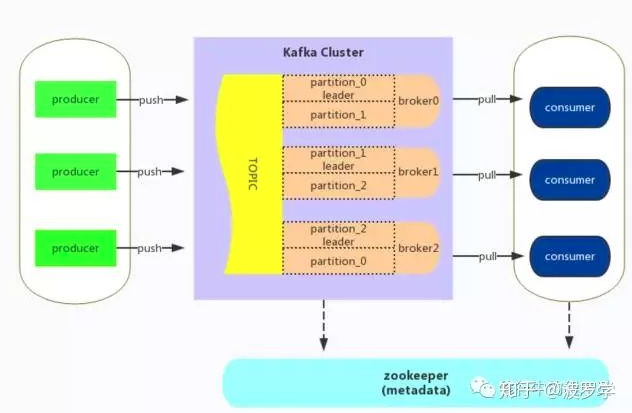
Kafka的架构相较于其他消息系统而言,比较简单。其整体流程简述如下
Producer 与指定 Topic 各分区 Partition 的 Leader 连接,从而将消息 push 到 Broker 中。
Broker 可理解消息系统的中间代理,将消息写入磁盘实现持久化,并可对消息复制备份。
Consumer 采用 pull 的方式主动获取 broker 中指定 Topic 的消息,并进行处理。
Zookeeper负责Kafka服务相关metadata的存储,如broker,topic和consumer等信息的存储。
注:zookeeper是一个分布式协调服务,分布式应用可基于它实现同步服务,配置维护和命名服务等。此篇文章不做介绍,以后有时间再做总结!
下面对涉及的各个组件作详细介绍。
主题Topic
首先,Kafka中的消息以Topic分类管理。在Kafka中,一个topic可被多个Consumer订阅。通过集群管理,每个Topic可由多个Partition组成。如下图
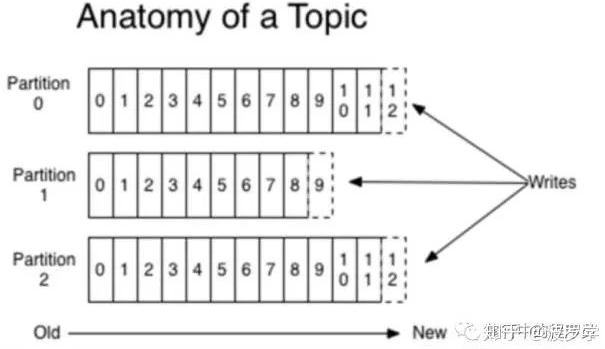
从上图可以看出,Topic中数据是顺序不可变序列,采用log追加方式写入,因而kafka中无因随机写入导致性能低下的问题。
Topic的数据可存储在多个partition中,即可存放在不同的服务器上。这可使Topic大小不限于一台server容量。同时,消息存在多个partition上,可以实现Topic上消息的并发访问。
Kafka中数据不会因被consumer消费后而丢失,而是通过配置指定消息保存时长。Topic中每个partition中的消息都有一个唯一的标识,也称为offset。因数据不会因消费而丢失,所以只要consumer指定offset,一个消息可被不同的consumer多次消费。
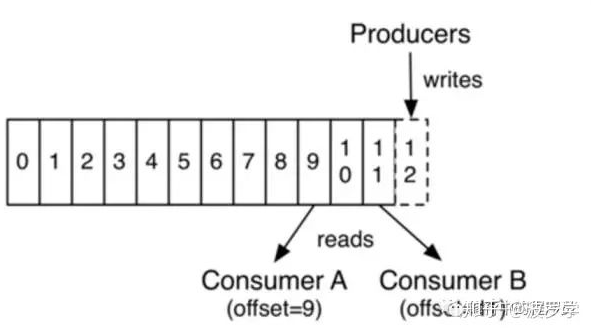
基于此,消息获取即可采用顺序访问,我们也可以指定任意offset随机访问,且不会对其他consumer产生影响。
分布式Distribution
Kafka 的集群分布式主要涉及两个内容:Partition 分区与 Replication 备份。
Partition 实现将 Topic 中的各个消息存储到不同的分区中,从而分布在不同的 Kafka 节点之上,使 Topic 的数据大小不限于一台 Server。
Replication 主要用于容错,对一个 Partition 复制多份,存储在不同 kafka 节点上。这可防止因某一分区数据丢失而导致错误。
虽然 Relication 复制 Partition 多份,但其中只有一个为 Leader 角色,其余 Partition 角色皆为 Follower。Producer 发布消息都是由Leader 负责写入,并同步到其他的 Follower 分区中。如果 Leader 失效,则某个 Follower 会自动替换,成为新的Leader分区。此时,Follower 可能落后于 Leader,所以从所有 Follower 中选择一个”up-to-date”的分区。
关于性能方面,考虑 Leader 不但承载了客户的连接与消息写入,还负责将消息同步至不同的 Follower 分区上,性能开销较大。因此,不同 Partition 的 Leader 分布在不同的 kafka 节点上,从而防止某个节点压力过载。
为了更好了解 Partition 与 Replication 关系。举个例子,假设现有一个 Topic 名为 spark_topic,其 Partition 分区数量为 3,Replication 备份因子为 2。则效果如下图
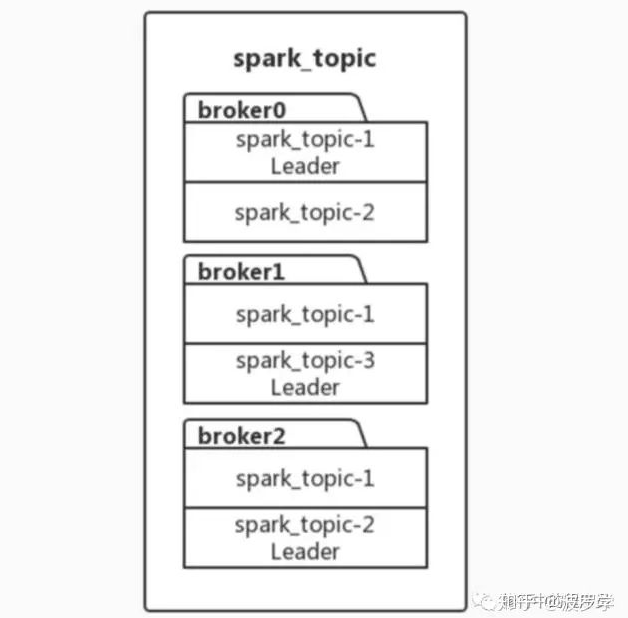
spark_topic存在spark_topic-1,spark_topic-2,spark_topic-3共三个分区。而每个分区均有两处备份,如spark_topic-1,其同时存在于kafka节点broker0与broker1上,其中broker01上的分区角色为Leader。
消费者Consumer
Consumer 负责消费消息。Kafka 中 Consumer 消费消息采用 fetch 方式主动拉取,这种方式的好处是 Consumer 客户端能根据自己的处理消息能力决定消息获取的速度与批量获取的数量,从而防止系统过载。
Kafka 的消息并不会因为消息被 Consumer 消费而丢失,因而其提供一个唯一的标识 offset 实现消息的顺序获取,而 offset 需要 consumer 自行维护,非 kafka 节点服务管理。这不同于传统的消息系统。在 Kafka 集群中,消费者的信息与 offset 在 zookeeper 也有保存维护,Consumer 会间歇性向 zookeeper 同步 offset。
Kafka 的 Consumer 提供分组功能,每个 Consumer 都属于一个分组。那分组的作用是什么呢?
类似queue模式,一个Consumer分组的多个Consumer订阅同一个Topic,一条消息只分发给其中一个Consumer,实现负载均衡效果。
发布订阅模式,而不同组的多个Consumer订阅同一个Topic,一条消息会广播给在不同分组的所有Consumer。
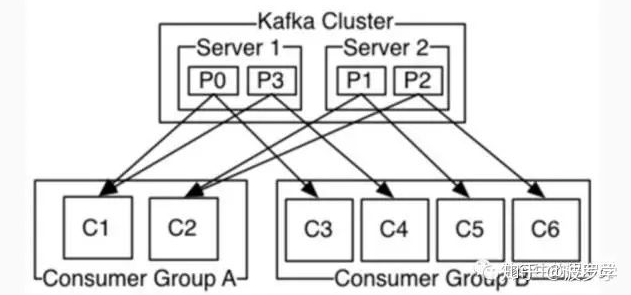
请注意,在 Kafka 中,同一 Consumer 分组中,一个 Consumer 只能订阅一个 Topic 中的 Partition,因而在一个 Consumer 分组中,同时订阅同一个 Topic 的 Consumer 的个数不能超过 Partition 分区数。可参看上图所示。
同样,为减少网络 IO 开销,Consumer 可采用 batch fetch 方式实现一次批量获取多条消息。
应用场景
下面是一些官网介绍的 Kafka 应用场景,包括消息系统、网站行为跟踪、应用监控、日志收集等等。
消息系统
Kafka 可以作为传统消息系统的替代。相比传统消息,Kafka 有更高的吞吐量、拥有内置的分区 Partition、复制备份高容错能力。
传统消息系统对高吞吐量没有过高要求,但 kafka 的低延迟特性和强大的备份容错能力是传统消息所必须的。
网站行为追踪
Kafka 可用于用户行为追踪,通过将用户行为数据发送给 Kafka。以此为基础,实现用户行为在线与离线分析,可用于网站实时监控与异常行为拦截等。
日志收集
Kafka 可以作为日志收集解决方案。日志收集通常是将不同服务器的日志文件收集到一个中心区域,Kafka 实现了对日志文件数据进行抽象,统一了处理接口。Kafka 低延迟,支持不同的日志数据源,分布式消费易于扩展,可同时将数据提供给hdfs、storm、监控软件等等。
应用监控
Kafka可用于监控运行中的应用系统。如收集分布式应用的数据进行聚合计算,进行分析检测异常情况。
个人感觉,本质和网站行为分析异常监控有异曲同工之处,只不过所监控的数据对象不同罢了。
结束
本文总结了大数据中常用的消息队列服务 Kafka。本篇主要从架构角度介绍。个人感觉,介绍系统架构比操作实战更加困难,文章如有错误,请帮忙请指正。
博文地址:快速了解 Kafka 基础架构
