配置数据#
本文具体讲讲如何在 Backtrader 中配置数据源,也就是 DataFeed。
我会先演示如何给 Backtrader 添加 CSV 数据源。然后,再介绍 Backtrader 中最常用的两种 DataFeed 的使用。
添加数据#
给 Backtrader 加载数据源分为两步:创建 DataFeed,然后通过 cerebro.adddata 加载到系统。
data = bt.feeds.{DataFeedClass}
cerebro.adddata(data)Backtrader 提供了种类繁多的 DataFeedClass,可用于对接处理不同的数据源,如 CSV 文件、Pandas DataFrame 或者其他自定义的数据类。
下面用 CSV 数据文件作为演示。先从 Backtrader 仓库下载 Oracle 1995 年至 2014 年的行情数据文件 orcl-1995-2014.csv。
开始编写代码吧。
使用 bt.feeds.GenericCSVData 读取 CSV 文件:
data = bt.feeds.GenericCSVData(
dataname="./orcl-1995-2014.txt",
dtformat="%Y-%m-%d",
)指定数据文件的路径和设置日期格式。
GenericCSVData 能适应各种格式的 CSV 文件,是一个通用的读取 CSV 行情数据的 DataFeed 类。
创建 DataFeed 后,通过 cerebro.adddata(data) 将其加载到回测引擎中。
cerebro.adddata(data)完整脚本:
import backtrader as bt
def main():
cerebro = bt.Cerebro()
data = bt.feeds.GenericCSVData(
dataname="./orcl-1995-2014.txt", dtformat="%Y-%m-%d",
)
cerebro.adddata(data)
cerebro.run()
cerebro.plot()
if __name__ == "__main__":
main()运行代码后,图表中就能看到价格行情了。
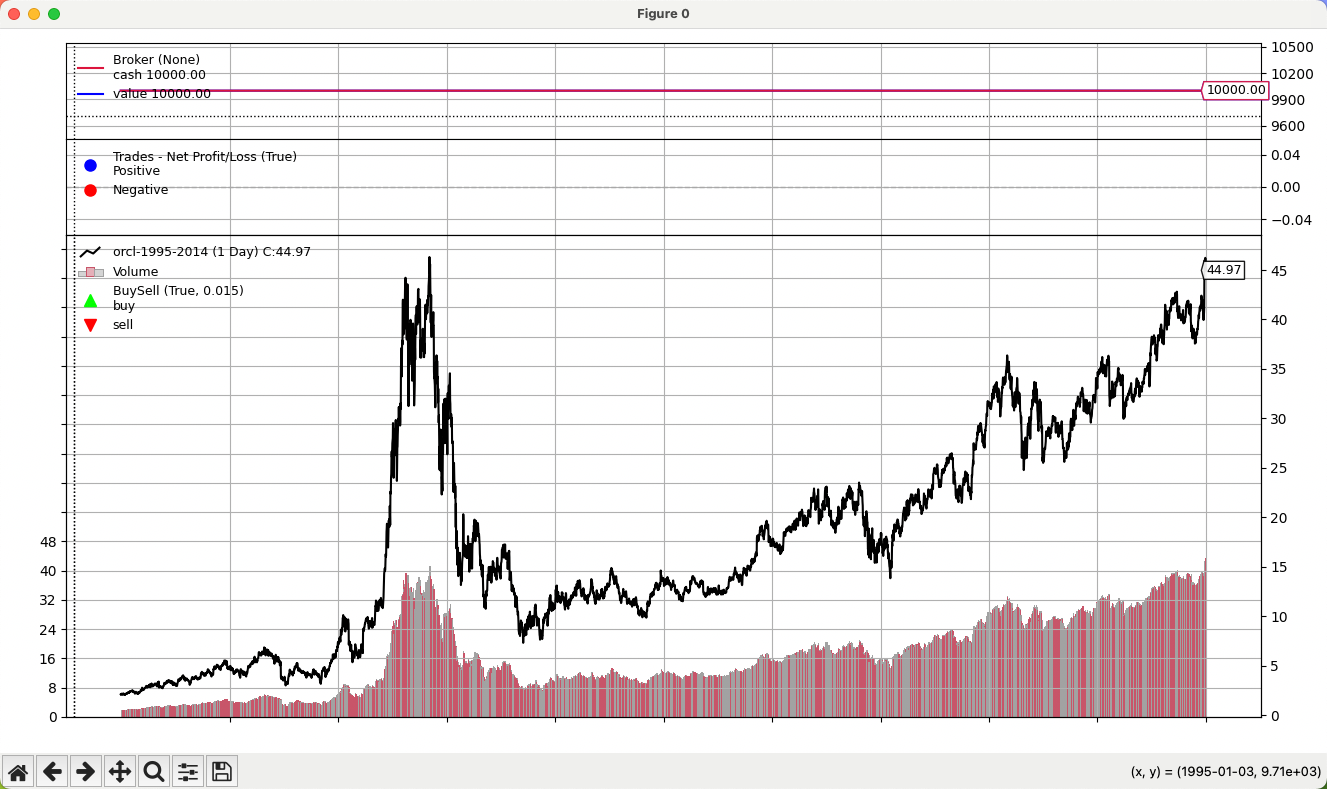
Pandas 数据源#
前面通过 GenericCSVData 加载远程 CSV 文件。Backtrader 还支持其他数据获取方式,最常用的是基于 Pandas DataFrame 创建 DataFeed。
依赖 pandas 的灵活性,这种方式能极大扩展数据渠道,无论是本地文件、关系型数据库还是远程 API(如 yfinance、tushare、akshare)都能搞定。
好,我们直接来看代码。
现在用 yfinance 下载 BTC-USD 从 2024-01-01 到 2025-11-10 的行情数据:
cerebro = bt.Cerebro()
df = yf.download("BTC-USD", start="2024-01-01", end='2025-11-10', multi_level_index=False)
data = bt.feeds.PandasData(dataname=df)
cerebro.adddata(data)
cerebro.run()
cerebro.plot(style='bar')注:使用新版 yfinance 时需设置 multi_level_index=False,否则多级索引可能导致加载失败。
输出绘图如下所示:
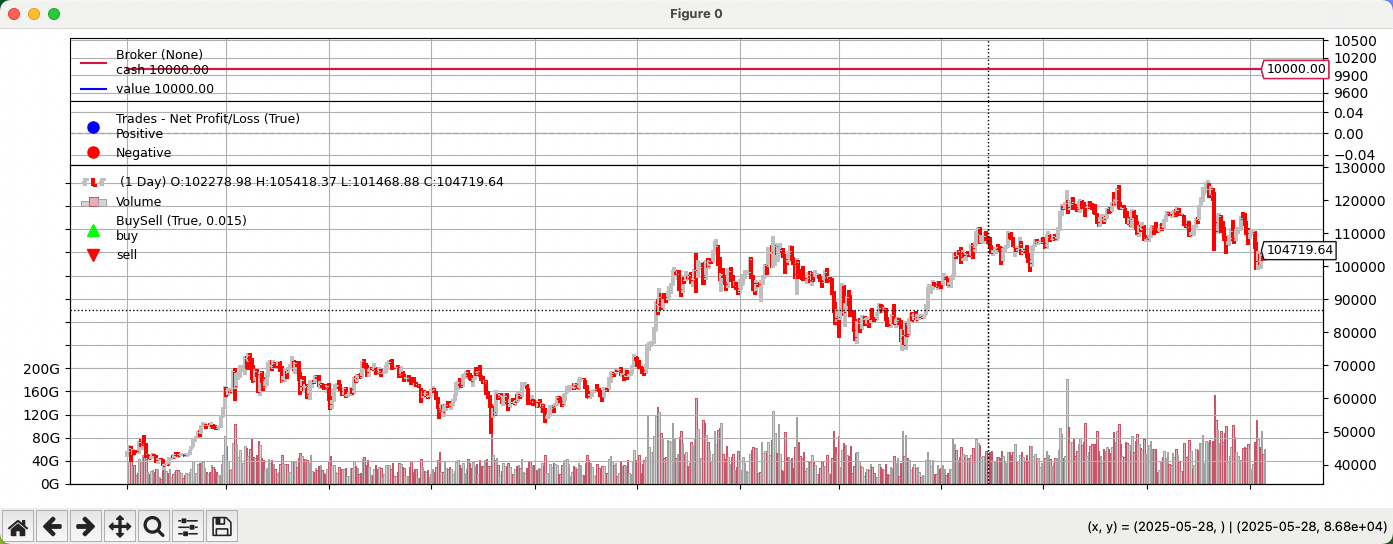
如上所示,先用 yfinance 获取指定品种和时间段的数据得到 DataFrame,然后传递给 PandasData 即可创建 Backtrader 可用的数据源。
PandasData 对传入的数据有一定要求:索引为时间,数据列需包含 open、high、low、close、volume 等。列名大写(如 Open、High、Low、Close)也可,PandasData 内部会自动转为小写。
准备工作做完后,就可以用 bt.feeds.PandasData 包装 DataFrame,然后通过 cerebro.adddata() 添加到回测系统中。
小结#
Backtrader 的数据能力非常强大,本文只是简单介绍了创建和添加数据。除此,Backtrader 还提供了其他丰富的数据源类。
大部分情况下,GenericCSVData 和 PandasData 已能满足需求。如有自定义数据列的需求,Backtrader 也支持自定义数据。
添加数据部分,除了 cerebro.adddata 直接添加,还可以重放、重采样数据,模拟实际交易环境。
下一节,我们学习如何编写交易策略。